日本語のCloud Architect 模擬試験を受けると合否しか表示されませんが、英語のCloud Architect 模擬試験では解説(英語)が付随されています。
問題と選択肢は日本語で、は英語を翻訳するとGoogle Cloud Platform について理解度が進むので勉強中の方にお薦めします
2018年9月27日時点の模擬試験に英語を翻訳にかけた解説文を下記に記載しております。
※ Google 翻訳の文章をそのままコピペしてるので文章に違和感あります。
アクセス頻度の低いデータをクラウドに移行することによるコスト削減を検討しています。データを移行した後も、履歴グラフ更新のため、月に 1 回程度はデータにアクセスします。また、5 年以上古いデータは必要ありません。どのような方法でデータを保存して管理すべきでしょうか。
- A. Google Cloud Storage を使用し、マルチリージョンのバケットに保存する。5 年以上古いデータを削除するように、オブジェクト ライフサイクル管理ポリシーを設定する。
- B. Google Cloud Storage を使用し、マルチリージョンのバケットに保存する。5 年以上古いデータのストレージ クラスをColdline に変更するように、オブジェクト ライフサイクル管理ポリシーを設定する。
- C. Google Cloud Storage を使用し、Nearline バケットに保存する。5 年以上古いデータを削除するように、オブジェクト ライフサイクル管理ポリシーを設定する。
- D. Google Cloud Storage を使用し、Nearline バケットに保存する。5 年以上古いデータのストレージ クラスをColdline に変更するように、オブジェクト ライフサイクル管理ポリシーを設定する。
フィードバック
C(正解) – アクセスパターンはNearline ストレージクラスの要件に適合し、Nearlineはマルチリージョンよりもコスト効率の高いストレージアプローチです。データを削除するためのオブジェクトライフサイクル管理ポリシーは、ストレージクラスをColdlineに変更するのに対して正しいです。
AとB – マルチリージョン ストレージクラスが正しくありません。
D – ストレージクラスをColdlineに変更するのは間違っています。
考察
データは月に1 回程度にアクセスする。そして、5 年以上古いデータは不必要と指定している。
その為、月に一度程度ならのアクセスなら「Nearline」、オブジェクト ライフサイクル管理ポリシーを使用して、5年以上のデータは削除するように設定する。
※コスト削減と言っているので、5年以上のデータを「ColdLine」での保存はコストがかかるにでデータ削除になると思われる。
会社のアーキテクチャは以下の図のようになっています。リージョン 1 とリージョン 2 でデータを同期を維持する必要があります。どのプロダクトを使用すべきでしょうか。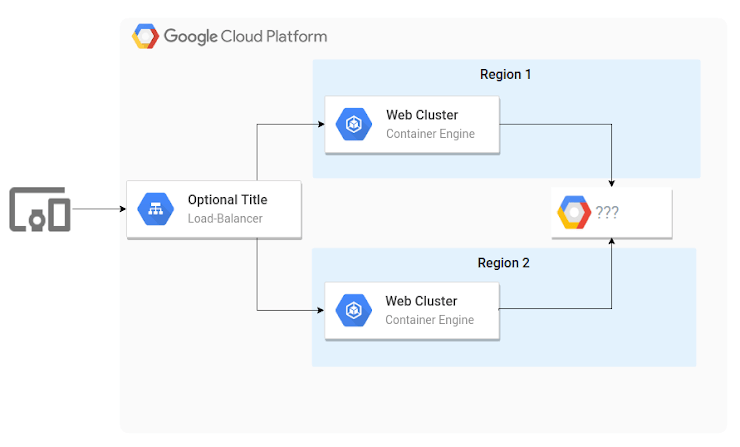
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Storage
- D. Google Cloud Datastore
フィードバック
C(正解) – Google Cloud Storage は、地域間でデータを自動的に同期するマルチリージョナルバケットをサポートしています。
A – Google Cloud SQL インスタンスは、単一の地域内に配置されます。
B – Google Cloud Bigtable のデータは1つの地域に保存されます。
D – Google Cloud Datastore は1つの地域に保存されます。
考察
Google Cloud Load Balancer でGoogle Container Engine(Kubernetes Engine) でリージョン間負荷分散の使用している。
求めているのが、各リージョンで同期を行える事を希望している。
マルチリージョンが行える「Google Cloud Storage」を選択するのが正しい。
※Google Cloud Datastore でもマルチリージョンでも行えるが、名称がGoogle Container Engine だったときには行えなかったからだろうか?
大規模なウェブ アプリケーションを構築しています。各チームはアプリケーションの特定のコンポーネントを専属で担当し、それぞれ独立したプロジェクトでの管理を希望しています。サービス間の通信には、RFC1918 アドレス空間を使うことが検討されています。どうすればよいですか。
- A. 各サービスを、同じVPC 内の 1 つのプロジェクトにデプロイする。
- B. 共有VPC を設定し、共有VPC プロジェクトのサービスとして各プロジェクトを追加する。
- C. HTTPS プロトコルを使用して他のサービスと通信するように、各サービスを設定する。
- D. プロジェクトごとにグローバル ロードバランサを設定し、グローバル ロードバランサのIP アドレスを使用して各サービス間の通信を行う。
フィードバック
B(正解) – 共有VPCを使用することで、各チームが独自のアプリケーションリソースを個別に管理しながら、各アプリケーションがRFC1918アドレス空間を超えて安全に通信できるようになります。
A – サービスを1つのプロジェクトに展開すると、すべてのチームが同じプロジェクトリソースにアクセスして管理します。これは、関係するチームの数が増えるにつれて、管理および制御が難しい。
C – HTTPSは有効なオプションですが、この回答では個々のプロジェクトの管理を確実にする必要はありません。
D – グローバルロードバランサはパブリックIPアドレスを使用するため、RFC1918アドレス空間での通信要件に準拠していません。
考察
各プロジェクトからプライベートIPアドレス(RFC1918)を利用して特定のアプリケーションにアクセスしたいと言っている。
設定が容易にできる「共有VPC」を選ぶ。
セキュリティ カメラの映像を収集して、Google Cloud Storage に保存しています。最初の30 日間は、映像を定期的に処理して、脅威の検出、対象物の検出、傾向の分析、不審な行為の検出を行います。全データの保存コストを最小限に抑えるには、どのような方法で動画を保存すればよいですか。
- A. 最初の30 日間はGoogle Cloud Regional Storage を使用し、その後はColdline Storage に移動する。
- B. 最初の30 日間はGoogle Cloud Nearline Storage を使用し、その後はColdline Storage に移動する。
- C. 最初の30 日間はGoogle Cloud Regional Storage を使用し、その後はNearline Storage に移動する。
- D. 最初の30 日間はGoogle Cloud Regional Storage を使用し、その後はGoogle 永続ディスクに移動する。
フィードバック
A(正解) – 最初の30日以内にデータに頻繁にアクセスするため、Google Cloud Regional Storage を使用すると、データの保存とアクセスに最も費用対効果の高いソリューションが有効になります。30日以上経過した動画の場合、Google Cloud Coldline Storage はアクセスされないため、最も費用対効果の高いソリューションを提供します。
B – Google Cloud Storage Nearline は、長期間のビデオストレージには費用対効果がありますが、頻繁にデータがアクセスされるため、最初の30日間は有効なソリューションではありません。
C – Google Cloud Storage Nearline は最初の30日間で最も費用対効果の高いソリューションですが、長期保存には費用対効果がありません。
D – Google Cloud Storage Regional は最初の30日間で最も費用対効果の高いソリューションですが、Google Persistent Disk にデータを保存することは、長期間のストレージには費用対効果がありません。
考察
最初の30日のデータは、定期的に処理(アクセス)を行い、30日移行のデータはどうするのかも指定がなく、全データの保存コストを最小限と指定されている。
マルチリージョンという指定がないため、単一リージョン内の「Regional」を30日間保存させ、30日以降のデータは削除ではなく、保存するようなので最もコストがかからない「Coldline」を選択する
※Google Persistent Disk (永続ディスク)は、$0.040 /月(GB 単位)とMulti-Regional より高く、長期保存には向かない。
以下に示す Google Cloud Deployment Manager マニフェストをデプロイしようとしています。チームは、インスタンス グループを1 インスタンスのみから始めて3 インスタンスに拡張することを望んでいます。デプロイを成功させるには、どうすればよいですか。
- A. 異なるゾーンを選択する。
- B. カスタムのsourceImage を使用する。
- C. ネットワーク インターフェースを削除する。
- D. インスタンス グループ テンプレートから2 番目のディスクを削除する。
フィードバック
D(正解) – 2番目のディスクは、読み取り/書き込みモードで1つのインスタンスにのみ接続できます。
A – ゾーンの選択は、開始されたインスタンスの数に影響を与えません。
B – カスタムsourceImageを使用しても、開始されたインスタンスの数には影響しません。
C – インスタンスには少なくとも1つのネットワークインターフェイスが必要です。ネットワークインターフェイスを削除すると、無効な構成が作成されます。
次の図に示すようなCI/CD パイプライン プロセスがあります。ボックス 1、2、3 ではどのGCP サービスを使用する必要がありますか。
- A. Google Cloud Storage、Google Cloud Pub/Sub、Google Compute Engine
- B. Google Cloud Storage、Google Cloud Container Builder、Google Container Engine
- C. Google Cloud Source Repositories、Google Cloud Storage、Google Container Engine
- D. Google Cloud Source Repositories、Google Cloud Container Builder、Google Container Engine
フィードバック
D(正解) – Google Cloud Source Repositories は、Gitバージョン管理開発環境を提供します。Google Cloud Container Builder は、Google Cloud Source Repository などのソースリポジトリからドッカーイメージを作成します。最後に、Google Container Engine は、Jenkinのデプロイメントパイプラインから受け取ったドッカーコンテナを実行して管理することができます。
A – Google Cloud StorageとGoogle Cloud Pub/Sub では、アプリケーションコードを管理または導入する手段は提供されていません。
B – Google Cloud Shellはドッカー画像を作成する手段を提供しないため、ソースコードはGoogle Cloud Storageに保存できますが、Google Cloud Shellは適切なソリューションではありません。
C – このオプションは、必要なドッカー画像を作成するソリューションを提供しません。
考察
Google Cloud Source Repositories からGoogle Cloud Container Builder は一連の流れになる。
本番環境トラフィックを提供するアプリケーションをGoogle App Engine で実行しています。リスクを伴うものの必要な変更をデプロイすることを考えています。適切にコーディングされていないと、サービスが停止する可能性があります。アプリケーションの開発中に、ライブユーザーのトラフィックによってのみ適切にテストできることがわかりました。どのように機能をテストすればよいですか。
- A. アプリケーションの新しいバージョンを一時的にデプロイした後、ロールバックする。
- B. 新しいアプリで第2のプロジェクトを別個に作成し、ユーザーをオンボードする。
- C. 第2のGoogle App Engine サービスをセットアップした後、新しいサービスにアクセスするようにクライアントのサブセットを更新する。
- D. 新しいバージョンのアプリケーションをデプロイし、トラフィックの分割を使用してトラフィックのわずかな部分をそれに送信する
フィードバック
D(正解) – 新しいバージョンをデフォルトバージョンとして割り当てずに展開しても、アプリケーションのダウンタイムは発生しません。トラフィック分割を使用すると、少量のトラフィックを新しいバージョンに簡単にリダイレクトすることができます。また、アプリケーションのダウンタイムなしにすばやく元に戻すこともできます。
A – デフォルトでアプリケーションバージョンを展開するには、すべてのトラフィックを新しいバージョンに移動する必要があります。これはすべてのユーザーに影響を与え、サービスを無効にする可能性があります。
B – 2番目のプロジェクトを導入するには、データ同期が必要で、新しいアプリケーションにトラフィックを誘導するための外部トラフィック分割ソリューションが必要です。これは可能ですが、Google App Engine ではこれらの手動手順は必要ありません。
C – Google App Engine サービスは、さまざまなサービスロジックをホストするためのものです。異なるサービスを使用するには、展開プロセスを認識し、どのサービスにアクセスしているコンシューマ側から管理するためにサービスのコンシューマを手動で構成する必要があります。
アプリケーションのマイクロサービスの1つに、断続的なパフォーマンスの問題があります。問題が発生した時点で監視してはいませんが、問題発生時に特定のログが発生します。問題が発生している間に、マシンをデバッグする必要があります。どうすればよいですか。
- A. マイクロサービスを実行しているマシンの1つにログインし、ログストームを待つ。
- B. Google Stackdriver Error Reporting ダッシュボードで、問題が発生したときのパターンを探す。
- C. 時間がかかりすぎている部分がわかるよう、トレースをGoogle Stackdriver Trace に送信するようにマイクロサービスを設定する。
- D. Google Stackdriver Logging でログ指標を設定した後、ログの行数が増加し閾値を超えたら通知するようにアラートを設定する。
フィードバック
D(正解) – ログラインのバーストがあることを知っているので、それらのラインを識別するメトリックを設定できます。Google Stackdriverを使用すると、エラーが検出されたときにすぐに通知できるテキスト、電子メール、またはメッセージングアラートを設定して、システムにデバッグすることができます。
A – 個々のマシンにログインすると、複数のマシンが構成に含まれる可能性があり、断続的なパフォーマンスの問題と対話する機会が減るため、特定のパフォーマンスの問題が発生することはありません。
B – エラー・レポートは、適切な形式のスタック・トレースでない限り、ログ・ラインを必ずしも捕捉するとは限りません。さらに、パターンがあるという理由だけで、いつどこでデバッグするのかを正確に知ることはできません。
C – Google Stackdriver Traceは、どこの時間が費やされているかを教えてくれるかもしれませんが、一般的にトレースのサンプルしか送信しないため、問題が発生している正確なホストに迷惑をかけません。問題がいつ起こっているかを正確に通知するためのトレースには警告もありません。
考察
問題が起きると特定のログが発生するのは把握できているが、監視していない状態なので、
問題が起きたらアラートがなるようにするために、Google Stackdriver Logging を導入し、ログの収集及び監査を設定する。
この質問については、Dress4Win の事例紹介を参照してください。
Dress4Win は将来的にGoogle Cloud にデータ分析をデプロイすることを検討しています。どのオプションがビジネス要件および技術要件を満たしていますか。
- A. Google Cloud Dataproc の現在の技術環境から現在のジョブを実行する。
- B. 現在のすべてのデータジョブを確認し、最も重要なジョブを特定して、データの保存およびクエリを実行するためのGoogle BigQuery テーブルを作成する。
- C. 現在のすべてのデータジョブを確認し、最も重要なジョブを特定して、データを処理するためのGoogle Cloud Dataflow パイプラインを開発する。
- D. Hadoop / Spark クラスタをGoogle Compute Engine 仮想マシンにデプロイし、現在の技術環境から現在のジョブを移動して、Hadoop / Spark クラスタ上で実行する。
フィードバック
A(正解) – 現在のジョブを別のテクノロジに移行する必要はありません。可能な限り管理サービスを使用することが要件です。Google Cloud Dataproc を使用すると、管理対象サービスでGoogle Cloud Platform 内で現在のジョブを実行できます。
B – 既存のデータジョブをGoogle BigQuery などの別のテクノロジーに移行する必要はありません。
C – 既存のデータジョブをGoogle Cloud Dataflow などの別のテクノロジーに移行することは必須条件ではありません。
D – できるだけ管理サービスを使用することが要件です。現在のジョブは、Google Compute Engine のHadoop / Sparkクラスタ上で実行できますが、管理されたサービスソリューションではありません。
この質問については、Dress4Winのケーススタディを参照してください。
Dress4Winの開発者は、Google Cloud Platform を評価を行っています。開発者は、Google App Engine フレキシブル環境に簡単に移行できるアプリケーションを特定しました。Google Cloud SDK のツールを使用してコードをデプロイします。このソリューションによって満たされる技術要件はどれですか。2つ選択してください。
- A. 転送時も保存時もデータを暗号化する。
- B. 可能な限りマネージド サービスを使用する。
- C. クラウドに移行することで容量を削減できる本番環境サービスを特定する。
- D. 緊急時のクラウドへの本番環境のフェイルオーバーをサポートする。
- E. リソースをクラウドにプロビジョニングするための自動化フレームワークを評価して選択する。
- F. 本番環境のデータセンターとクラウド環境の間を複数のVPN で接続する。
フィードバック
B、E(正解) – 可能な限り管理サービスを使用することは、Google App Engine Flexible Environment を使用することによって満たされます。Google Cloud SDK を使用すると、Google App Engine Flexible Environment などのGoogle Cloud Platform リソースのプロビジョニングと管理が可能になります。
A – ソリューションはこの要件をサポートすることができますが、追加のソリューションコンポーネントをサポートする必要があるため、前述の要件を満たしません。
C – ソリューションはこの要件をサポートするかもしれませんが、特定のプロダクションサービスに関する情報と容量の節約方法についての情報はありません。
D – ソリューションはこの要件をサポートすることができますが、追加のソリューションコンポーネントをサポートする必要があるため、前述の要件を満たしません。
F – ソリューションはこの要件をサポートすることができますが、追加のソリューションコンポーネントをサポートする必要があるため、前述の要件を満たしません。
この質問については、Dress4Winのケーススタディを参照してください。
下のアーキテクチャ図は、Dress4winがユーザがアップロードした画像をラベル付けして圧縮するために構築しているイベントベースの処理パイプラインを示しています。どのGCP製品をボックス1,2,3で使用すべきですか?
- A. Google App Engine、Google Cloud Datastore、Google Cloud Dataflow
- B. Google App Engine、Google Cloud Dataflow、Google Cloud Functions
- C. Google Cloud Storage、Google Cloud Pub/Sub、Google Cloud Dataflow
- D. Google Cloud Dataflow、Google Cloud Pub/Sub、Google Cloud Functions
フィードバック
C(正解) – Google Cloud Storage API は、クライアントからの画像アップロード用の書き込み専用のバケットを簡単に許可し、アップロードイベントはGoogle Cloud Pub/Sub にプッシュされ、Google Cloud Functions をトリガーしてファイルを取得し、Google Cloud Vision API を通じてGoogle Cloud Pub/Sub にメタデータを追加します。ここでDataflowはメッセージを表示し、Google Cloud Storageからファイルを処理し、メタデータをGoogle Cloud SQLに格納します。
A – Google App Engine アプリは画像アップロードを受け付けるように書くことができますが、Google Cloud Datastore は画像ファイルを保存するためのものではありません。
B – Google App Engine アプリケーションは画像のアップロードを受け付けるように書くことができますが、Google Cloud Dataflow はGoogle Cloud Storage バケットまたはGoogle Cloud Pub/Sub のいずれかのトピックを必要とするため、イベント処理を待機します。Google Cloud Dataflow をGoogle App Engineに接続することは非常に珍しいアーキテクチャです。
D – 画像アップロードのためにGoogle Cloud Dataflow にユーザーを直接接続することは、ユーザーのアップロードトラフィックのバースト性を効率的に処理できないため、ユーザーに信頼できる体験を提供しません。
この質問については、Dress4Winのケーススタディを参照してください。
Dress4Winは、クラウドにデプロイされたテスト環境および開発環境でペネトレーション セキュリティ スキャンを実行したいと考えています。どのような方法でペネトレーション テストを実施する必要がありますか。
- A. Dress4Win に代わって通常のペネトレーション セキュリティ スキャンを実施するようにGoogle に通知する。
- B. セキュリティ スキャナをクラウド環境にデプロイし、各環境内でペネトレーション テストを実施する。
- C. オンプレミス スキャナを使用し、VPN でトラフィックをルーティングしてクラウド環境でペネトレーション テストを実施する。
- D. オンプレミス スキャナを使用し、公共のインターネットでトラフィックをルーティングしてクラウド環境でペネトレーション テストを実施する。
フィードバック
D(正解) – スキャナをクラウド環境外に配置すると、エンドユーザの侵入テストを最もよくエミュレートできます。環境にアクセスするために公共のインターネットを使用すると、エンドユーザのトラフィックが最もよくエミュレートされます。
A – Google は、自分のアプリケーションでセキュリティスキャンを実施している顧客に通知する必要はありません。
B – クラウド環境内にセキュリティスキャナを展開しても、エンドユーザーが通常アクセスする境界セキュリティ設定はテストされない可能性があります。これは、可能な限りエンドユーザトラフィックをエミュレートしません。
C – オンプレミス環境とクラウド環境の間でVPNを使用してセキュリティスキャナを展開しても、エンドユーザーが通常アクセスする境界セキュリティ設定はテストできません。VPNトラフィックは、パブリックインターネットトラフィックよりも高い信頼性を持ち、可能な限りエンドユーザトラフィックをエミュレートしません。
※日本語版のみ出題
この質問については、Dress4Winのケーススタディを参照してください。
Dress4Winのセキュリティ チームは、Google Cloud Platform(GCP)上の本番環境仮想マシン(VM)への外部SSH アクセスを無効にしました。オペレーション チームは、VM をリモート管理し、Docker コンテナを構築してpush し、Google Cloud Storage オブジェクトを管理する必要があります。どうすればよいですか。
- A. オペレーション エンジニアにGoogle Cloud Shell を使用するためのアクセス権を付与する。
- B. GCP に対するVPN 接続を設定し、クラウド VM へのSSH アクセスを許可する。
- C. オペレーション エンジニアがタスクを実行する必要があるときにクラウド VM への一時的なSSH アクセスを許可する新しいアクセス要求プロセスを開発する。
- D. オペレーション チームが特定のリモート プロシージャ コールを実行してタスクを遂行できるようにするAPI サービスを開発チームに作成させる。
フィードバック
日本語版のため、解説なし
※英語版のみ出題
あなたの会社のアーキテクチャが図に示されています。各Google Container Engine クラスタに新しいコードを自動的かつ同時に配置したいとします。どちらの方法を使うべきですか?
- A. Jenkinsなどのオートメーションツールを使用します。
- B. クラスタを変更してフェデレーションモードを有効にします。
- C. Google Cloud Shell とkubectlでParallel SSH を使用する。
- D. Google Cloud Container Builder を使用して新しい画像を公開します。
フィードバック
A(正解) – これは、これを自動的かつ同時に行う基準を満たしています。
B – フェデレーションモードでは連合形式での展開が可能ですが、それ以上のことはしませんが、質問の「自動」部分を有効にするためにはJenkinsのようなツールが必要です.Jenkinsでは必ずしもフェデレーションを有効にする必要があります。
C – これは非常に単純な例ではうまくいくかもしれませんが、複雑さが増すにつれて、これは扱いにくくなります。
D – Google Container Builder では、イメージを別のクラスタにプッシュする方法はなく、Google Container Registry に公開されています。
マルチペタバイトのデータセットをクラウドに移行することを計画しています。データセットは1日24時間利用できる必要があります。ビジネス アナリストには、SQL インターフェースの使用経験しかありません。データを最適化して分析を容易にするには、データをどのように保存する必要がありますか。
- A. データを Google BigQuery に読み込む。
- B. データを Google Cloud SQL に挿入する。
- C. フラット ファイルを Google Cloud Storage に格納する
- D. データを Google Cloud Datastore にストリーミングする。
フィードバック
Google BigQuery は、SQLインターフェースをサポートするこれらのGoogle 製品と、容易に利用できるように十分に高いSLA(99.9%)の唯一のものです。Google Cloud Storage にはSQLインターフェイスがありません。
米国中部リージョンにある本番環境Linux 仮想マシンのコピーを作成する必要があります。コピーの管理と、本番環境仮想マシンに変更があった場合のコピーの置換を、簡単に実行できるようにしたいと思っています。コピーは、米国東部リージョンの別のプロジェクトに新しいインスタンスとしてデプロイします。どのような手順で行う必要がありますか。
- A. Linux の dd およびnetcat コマンドを使用して、ルートディスクの内容をコピーし、米国東部リージョンの新しい仮想マシン インスタンスにストリーミングする。
- B. ルートディスクのスナップショットを作成し、米国東部リージョンに新しい仮想マシン インスタンスを作成するときに、そのスナップショットをルートディスクとして選択する。
- C. Linux のdd コマンドを使用してルートディスクからイメージ ファイルを作成し、イメージ ファイルから新しいディスクを作成した後、それを使用して米国東部リージョンに新しい仮想マシン インスタンスを作成する。
- D. ルートディスクのスナップショットを作成し、スナップショットからGoogle Cloud Storage にイメージ ファイルを作成した後、ルートディスクのイメージ ファイルを使用して米国東部リージョンに新しい仮想マシン インスタンスを作成する。
フィードバック
D(正解) – このアプローチはすべての要件を満たしています。クロスプロジェクトとクロスリージョンを処理するのは簡単です。
A – このアプローチは、既存のマシンのパフォーマンスに影響を与え、ネットワークのコストを大幅に引き上げます。
B – このアプローチでは、スナップショットが作成されたプロジェクトに制限されるため、新しいプロジェクトにVMを作成することはできません。
C – ddは、マウントされたディスクでは正しく動作しません。
お客様がストレージ プロダクトをGoogle Cloud Storage(GCS)に移行しています。データには個人識別情報(PII)とお客様の機密情報が含まれています。GCS にはどのようなセキュリティ戦略を使用する必要がありますか。
- A. 署名付きURL を使用して、オブジェクトへの時間制限付きアクセスを生成する。
- B. ユーザーにCloud IAM の読み取り専用アクセス権を付与し、バケットでデフォルトの ACL を使用する。
- C. ユーザーに Google Cloud Identity and Access Management(Cloud IAM)の役割を付与せず、バケットで詳細なACL を使用する。
- D. ランダム化されたバケット名とオブジェクト名を作成する。パブリック アクセスを有効にするが、Google アカウントを持たずにアクセスが必要なユーザーには特定のファイルURL のみを提供する。
フィードバック
C(正解) – データへのアクセスに最低限必要な特権を与え、間違った人へのアクセスを誤って許可するリスクを最小限に抑えます。
A – 署名されたURLが漏洩する可能性があります。
B – これは不必要に許されており、ユーザーはアクセスを得るために1つの許可しか必要としません。
D – これはまったくセキュリティとして知られている、あいまいさによるセキュリティです。
お客様が、会社のアプリケーションをGoogle Cloud Platform に移行しています。セキュリティ チームは、組織内のすべてのプロジェクトを詳細に把握する必要があります。あなたは、Google Cloud Resource Manager をプロビジョニングし、自分を組織管理者として設定します。Google Cloud Identity and Access Management(Cloud IAM)のどの役割を、セキュリティ チームに付与する必要がありますか。
- A. 組織閲覧者、プロジェクト オーナー
- B. 組織閲覧者、プロジェクト閲覧者
- C. 組織管理者、プロジェクト参照者
- D. プロジェクト オーナー、ネットワーク管理者
フィードバック
回答Bは、セキュリティチームがあなたの会社が生産したすべてのものへのアクセスのみを読み取るようにします。何か他のものは、偶然に、あるいはそうでなければ、物事を変更する能力を与えます。
最近のソフトウェア更新が原因となり、Google Cloud で稼働しているe コマース ウェブサイトが数時間クラッシュしました。CTO は、すべての重要な変更にバックアウト / ロールバック計画が必要であると判断しました。このウェブサイトは数百の仮想マシン(VM)にデプロイされ、重大な変更が頻繁に発生します。バックアウト / ロールバック計画を実装するには、どのアクションを実行する必要がありますか。2つ選択してください。
- A. Google Cloud Storage に保存されているウェブサイトの静的データファイルの Nearline コピーを作成する。
- B. Google Cloud Storage に保存されているウェブサイトの静的データファイルでオブジェクトのバージョニングを有効にする。
- C. ローリング更新を開始するときに、「update-instances」コマンドでマネージド インスタンス グループを使用する。
- D. プロジェクトでGoogle Cloud Deployment Manager(CDM)を有効にし、各変更を新しい DM テンプレートで定義する。
- E. 更新の前に各VM のスナップショットを作成し、新しいバージョンで障害が発生した場合はスナップショットからVM を復元する。
フィードバック
B(正解) – これは、静的コンテンツの最後の正常なバージョンが常に利用可能であることを保証するシームレスな方法です。
C(正解) – VMの管理を容易にし、Google Compute Engine が各インスタンスの更新を管理できるようにします。
A – このコピープロセスは信頼できず、同期をとるのが難しくなります。データの悪いバージョンがコピーに書き込まれると、ロールバックする方法もありません。
D – これにより、プロセスに多大なオーバーヘッドが加わり、以前のバージョンが変更された場合に予期しない動作につながる可能性のある異なるGoogle Cloud Deployment Manager(CDM)展開間の関連で競合が発生します。
E – このアプローチはうまく拡張されません。多くの管理作業が必要です。
企業のWebホスティングプラットフォームで、誤った実稼働展開の計画外のロールバックの影響を軽減する必要があります。QAプロセスの改善は80%の削減を達成しました。ロールバックの影響をさらに減らすために、さらに2つのアプローチを取ることができますか?(2つ選択)
- A. green-blue デプロイモデルを導入する。
- B. モノリシックなプラットフォームをマイクロサービスに分割する。
- C. QA 環境をカナリア リリースに置き換える。
- D. リレーショナル データベース システム上でプラットフォームへの依存を減らす。
- E. プラットフォームのリレーショナル データベース システムをNoSQL データベースに置き換える。
フィードバック
A(正解) – トラフィックを送信する前に、緑色の環境でアプリケーションを広範にテストすることができます。典型的には、2つの環境が同一でなければ、最高レベルのテスト保証が得られます。
B(正解) – より小さな、より漸進的な更新の更新を可能にします(各マイクロサービスは個別に更新することができます)。これにより、各ロールアウトでのエラーの可能性が減少します。
C – 一般的なリリース戦略から実績のあるステップを削除します。カナリーリリースプラットフォームはQAの代替品ではありません。追加する必要があります。
D – 実際の展開戦略に役立つわけではありません。他のタイプのデータストレージよりも障害が発生しやすいリレーショナルデータベースに固有の特性はありません。
E – NoSQLデータベースはリリース品質に役立つリレーショナルデータベースを提供していないため、実際には役に立たない。
リード ソフトウェア エンジニアは、新しいアプリケーションの設計では複数のウェブサーバーに分散されていないWebSocket と HTTP セッションを使用していると言っています。あなたは、このようなアプリケーションがGoogle Cloud Platform で正常に動作するよう助けたいと考えています。どうすればよいですか。
- A. HTTP ストリーミングを使用するようにWebSocket コードを変換するエンジニアの作業を手伝う。
- B. セキュリティ チームと協力して、WebSocket 接続の暗号化要件を確認する
- C. クラウド オペレーション チームおよびエンジニアと会って、ロードバランサのオプションを検討する。
- D. WebSocket とHTTP セッションに依存しない分散ユーザー セッション サービスを使用するようにアプリケーションを再設計するエンジニアの作業を手伝う。
フィードバック
C(正解) – GCPのHTTP(S)ロードバランサはネイティブでwebsocketトラフィックを処理します。クライアントと通信するためにWebSocketを使用するバックエンドは、スケールと可用性のためにHTTP(S)ロードバランサをフロントエンドとして使用できます。
A – GCPへの移行の一環としてウェブソケットから離れる魅力的な理由はありません。
B – とにかくこれは良い練習になるかもしれませんが、実際にはGCPの移行には関係しません。
D – GCPへの移行の一環としてウェブソケットから遠ざかる理由はありません。